What will a larger context window mean for your knowledge work?

Have you misunderstood context windows?
“XYZ model can handle even larger context lengths… So now you can put all your client documentation into one window and ask questions about it… Or upload all your successful proposals and ask it to analyse them”
But, can it?
Note. The context window in large language models (LLMs) refers to the max number of tokens (words) the model can take as inputs when generating text.
LLMs behave a lot like humans here. Ironically.
If you read a large book in one go, you will be unlikely to digest and accurately recall details from it. One reason for this might be the verbatim effect. This is a cognitive bias where humans recall the gist of information better than specific details; in the most meaningful and least detailed way possible.
#tipsforyournextpresentation.
LLMs behave the same.
They tend to recall the beginning, the end, and a few points that resonate (for varied reasons).

So context window size/ memory is important...
But to ensure you/ your Gen AI recalls information that is consistently accurate and reliable, there are a few more considerations.
E.g., What’s the specific ask? What existing knowledge is used? How well does it understand your request/the data it is given?
How might AI understand the unstructured data from your consulting work?
Scientists and ML engineers are still trying to understand how LLMs work. Even still, there are several ‘good practices’ we can already apply and experiment with. Even within a consulting context.
E.g.,
Understand the types of questions that users (consultants) will ask, and in what context (e.g, project/ service type)
Understand user expectations (junior, manager, senior) in typical use cases - and desire for a single definitive answer, or varied views.
Optimise how unstructured data is chunked and input, so it is easier for the model to process.
Fine-tune classification models to help the large language model better assign meaning and context to the data it is fed.
Employ agentic workflows to support the different types of analysis that users will want to run in sequence and/ or in tandem.
Etc.
The Discy way.
Consultants use Discy throughout their project work, so the AI has to help them come up to speed, analyse to greater depth, and assemble impactful insights.
To this aim, last year we introduced transcription and smart tags in Discy.
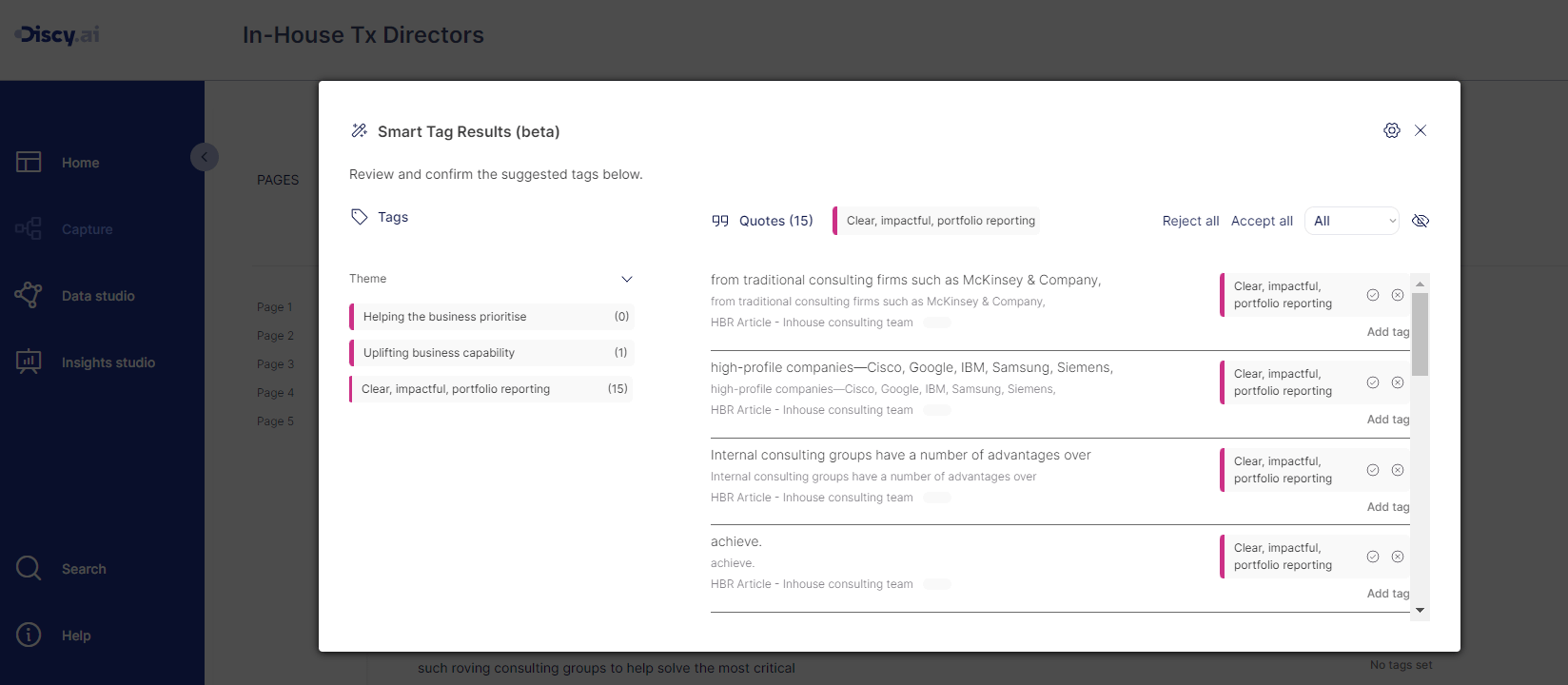
A smart tag is a 'code' suggested by Discy’s AI.
Discy 'tags' the text in the data that users input from their discovery work (e.g., interviews, surveys, files etc).
Firms train their own AI classifier model in Discy. Based on what their experts see as important to identify in documents and interviews.
The result is a 'living codebook'. Called upon by teams to help them tag and categorise their data.
This acts as both an accelerant and a map to keep them aligned on the big signs. A better place to start analysing in and across data sources. In which assumptions, biases and insights will either wilt or grow.
Next step. Summarising.
A few weeks ago, we rolled a few of our clients onto Discy’s new (beta) summarise feature.
More to come on what this is, and why we think it will be materially different!
***
Thanks for reading, have an insightful week!
***
Sounds like the product is making huge progress - well done guys